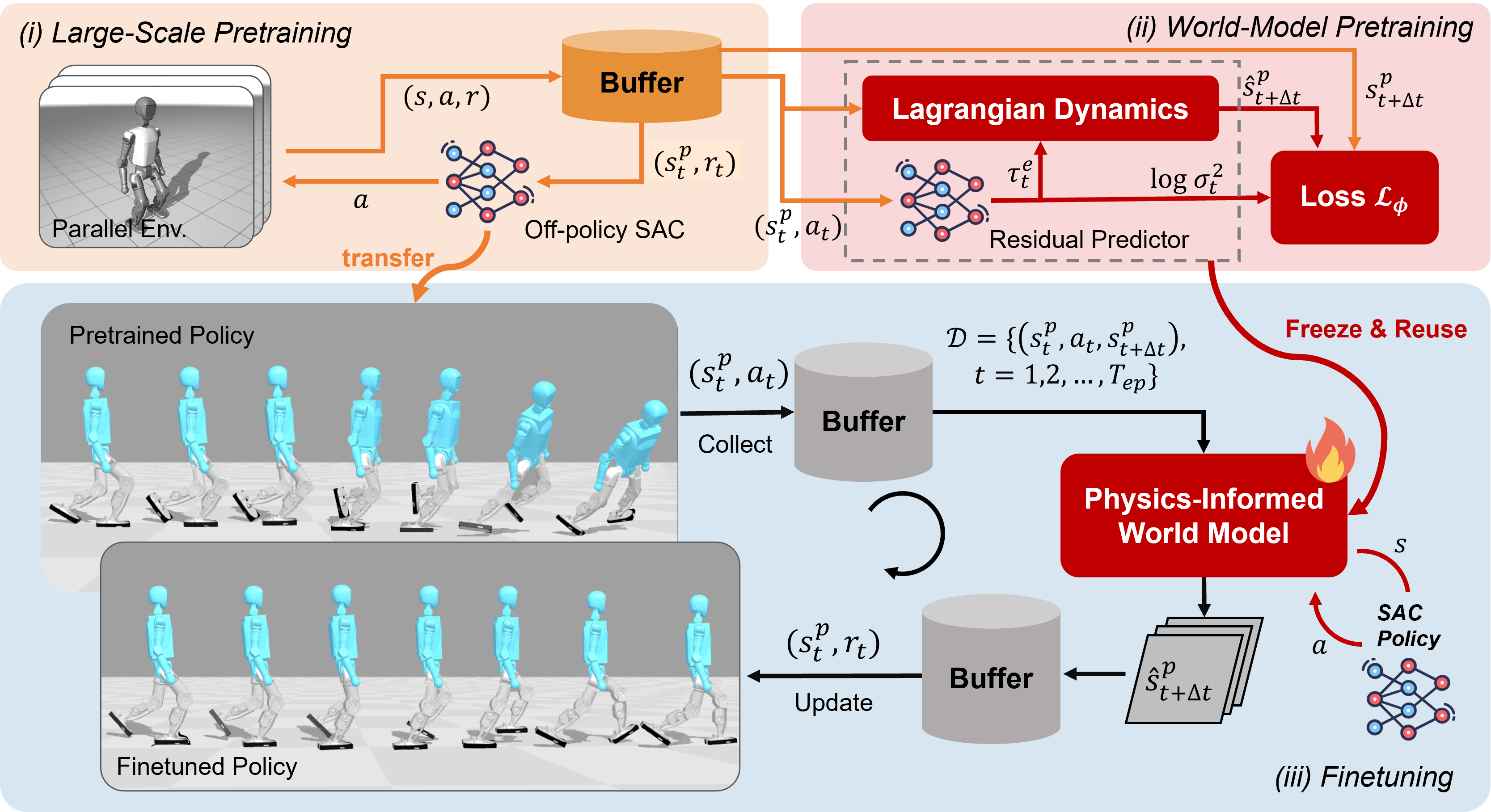
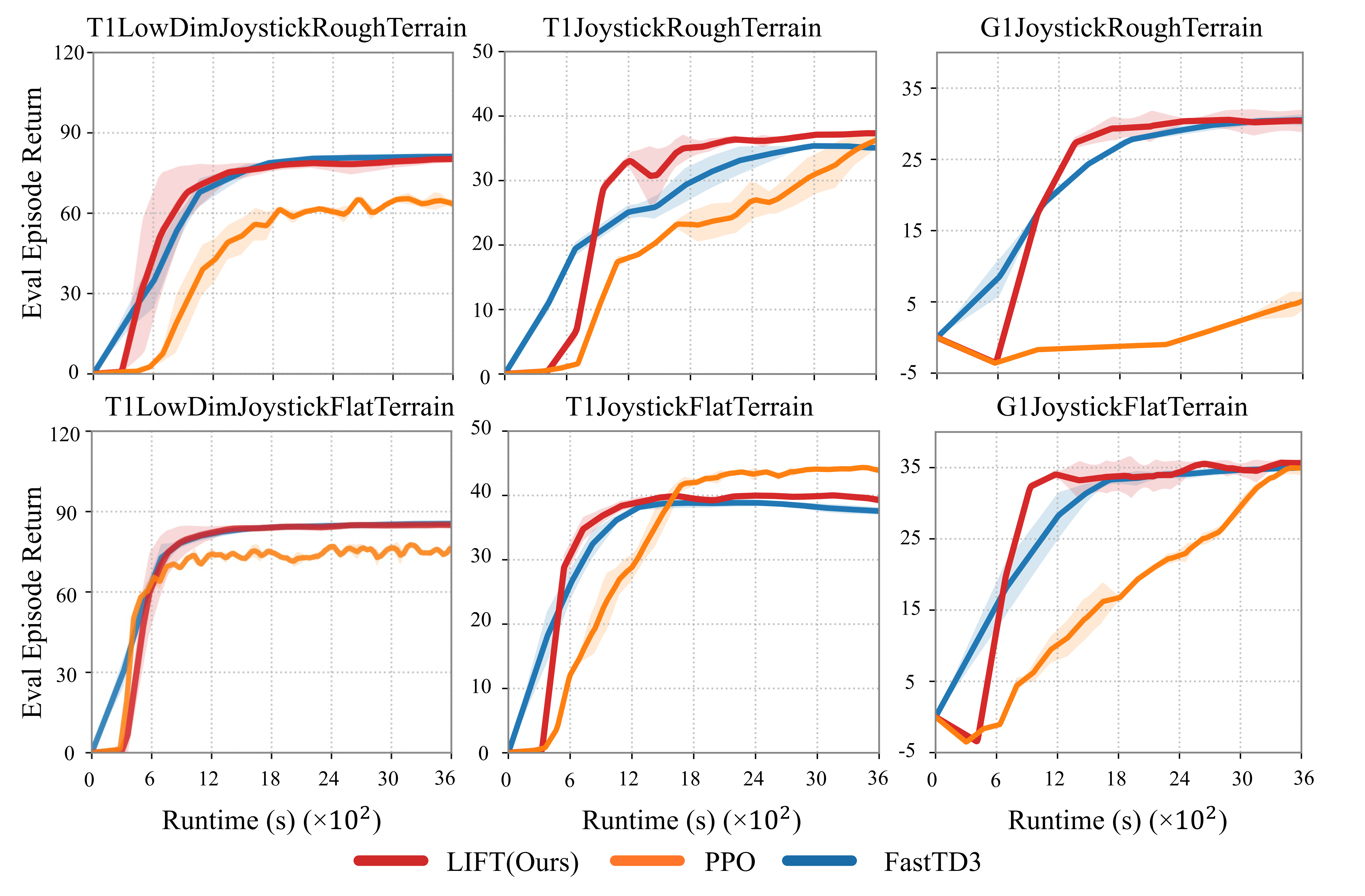
Reinforcement learning (RL) is widely used for humanoid control, with on-policy methods such as Proximal Policy Optimization (PPO) enabling robust training via large-scale parallel simulation and, in some cases, zero-shot deployment to real robots. However, the low sample efficiency of on-policy algorithms limits safe adaptation to new environments. Although off-policy RL and model-based RL have shown improved sample efficiency, the gap between large-scale pretraining and efficient finetuning on humanoids still exists. In this paper, we find that off-policy Soft Actor-Critic (SAC), with large-batch update and a high Update-To-Data (UTD) ratio, reliably supports large-scale pretraining of humanoid locomotion policies, achieving zero-shot deployment to real robots. For adaptation, we demonstrate that these SAC-pretrained policies can be finetuned in new environments and out-of-distribution tasks using model-based methods. Data collection in the new environment executes a deterministic policy while stochastic exploration is instead confined to a physics-informed world model. This separation mitigates the risks of random exploration during adaptation while preserving exploratory coverage for improvement. Overall, the approach couples the wall-clock efficiency of large-scale simulation during pretraining with the sample efficiency of model-based learning during fine-tuning.
Please watch the video on: YouTube
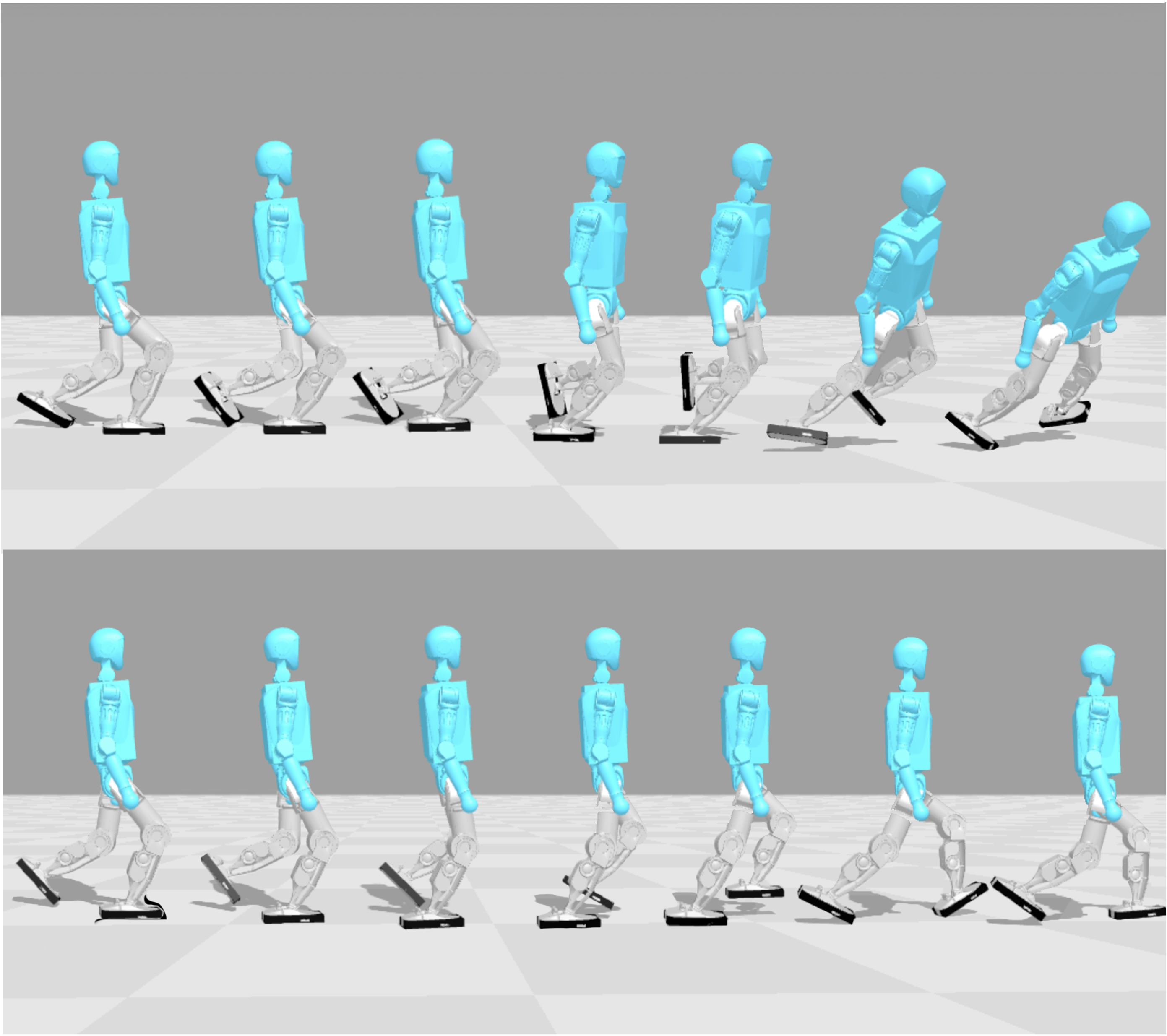
We conduct real-world fine-tuning experiments on the Booster T1 humanoid robot. We first pretrained a policy in the MuJoCo-Playground T1LowDimJoystickFlatTerrain task, where we removed most energy-related constraint terms and kept only the action-rate L2 penalty. Although this policy transfers well between simulators (MuJoCo -> Brax), the reduced energy constraints and flat-terrain pretraining lead to a failure in zero-shot sim-to-real transfer. We then used this policy as the initialization for real-world fine-tuning to evaluate the effectiveness of our method. As shown in the video, the policy begins with unstable behavior (0 s of data) and gradually improves as additional real-world experience is incorporated. After collecting 80–590 s of data, the robot exhibits increasingly upright posture, smoother gait patterns, and more stable forward velocity. These results demonstrate that our fine-tuning framework can successfully adapt a weak sim-to-real policy and make it substantially more robust after collecting only several minutes of data.
We reimplemented the observation and reward structure of BeyondMimic in JAX within MuJoCo Playground and used the Unitree motion dataset (LAFAN1) to pretrain a whole-body tracking policy for the Unitree G1 humanoid. We present these whole-body tracking results as preliminary evidence of LIFT’s broader applicability.